
Data Warehouse Integration
Overview
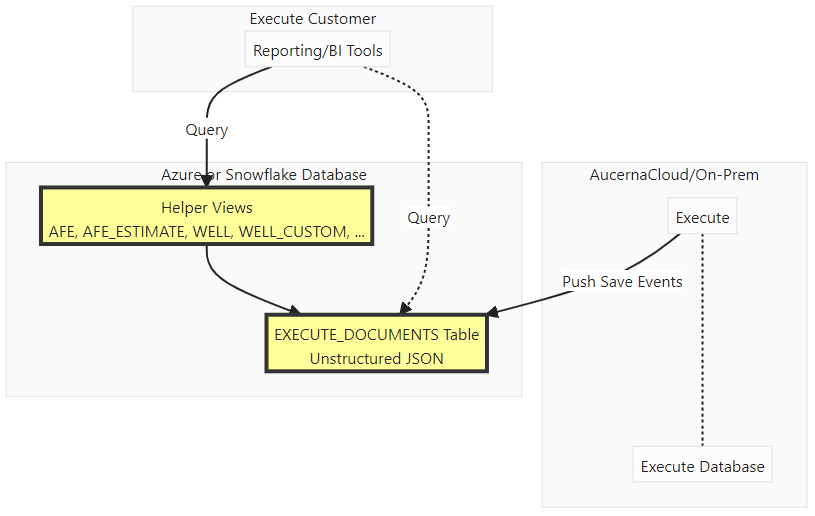
Execute's Data Warehousing functionality supports publishing Execute data in near real-time to an external database (AzureSQL or Snowflake) for data warehousing and reporting purposes. While this functionality is primarily intended to provide Quorum-hosted Execute customers with access to their data, it can also be useful for on-prem customers wishing to replicate their data into Snowflake or AzureSQL.
Execute's publish to Data Warehouse functionality is the most efficient way to extract ALL Execute data from Execute into an external database. It works by listening for low-level document (AFE, Well, Site, Project, AFE Type, User, ...) save events in Execute, queuing those, and periodically sending them across to the warehouse database in batches. This mechanism is very efficient so the interval for sending batches can be set to a fairly short interval if near real-time access to data is required.
Currently, Execute supports publishing to AzureSQL and Snowflake. The table below summarizes some key differences between the two environments. In general, Snowflake is the fastest and preferred option where it is available.
| AzureSQL | Snowflake | |
| Performance | good | great |
| Reporting Views | yes (slower to query) | yes |
| Materialized Views | yes (sower to insert/update) | no (not required) |
| Database Relationships | materialized views only | no |
For both AzureSQL and Snowflake, all document events are uploaded to the "EXECUTE_DOCUMENTS" table. Optionally, a set of reporting-focused views present that data in a set of simplified views that closely resemble the underlying tables in Execute.
Requirements
-
An Execute OData License is a platform-level license which allows customers to query Execute data using OData, as well as publish it to an External Data Warehouse.
-
An empty AzureSQL or Snowflake database and username/password for a user in that database with permissions to modify the schema and read/write/update/delete data.
By default, Quorum-hosted Execute environments are configured to prevent outbound connections. Prior to enabling this integration, a support request must be raised to allow this outbound traffic.
Schema
The primary table in warehouse schema is EXECUTE_DOCUMENTS. This table stores unstructured (JSON) content for ALL document types in Execute (AFEs, Users, Wells, Sites, ...). Execute publishes new document saves directly into this table.
The EXECUTE_DOCUMENTS table consists of the following columns.
| Column | Type | Notes |
| AUTHOR | GUID | DocumentID for the user who authored this version of the document |
| DATA | JSON | JSON data for the document |
| DATE | TIMESTAMP | Date this version of the document was created |
| DELETED | BOOLEAN | Is this document deleted? |
| ID | GUID | Document ID for this document |
| TYPE | VARCHAR | Document Type for this document (AFE, WELL, SITE, USER, PROJECT, ...) |
| VERSION | INT | Version for this document |
Reporting Tables/Views
In addition, Execute can be configured to create a series of *reporting* views on the data in "EXECUTE_DOCUMENTS" to simplify reporting and the transition for customers who have existing queries written against the Execute database.
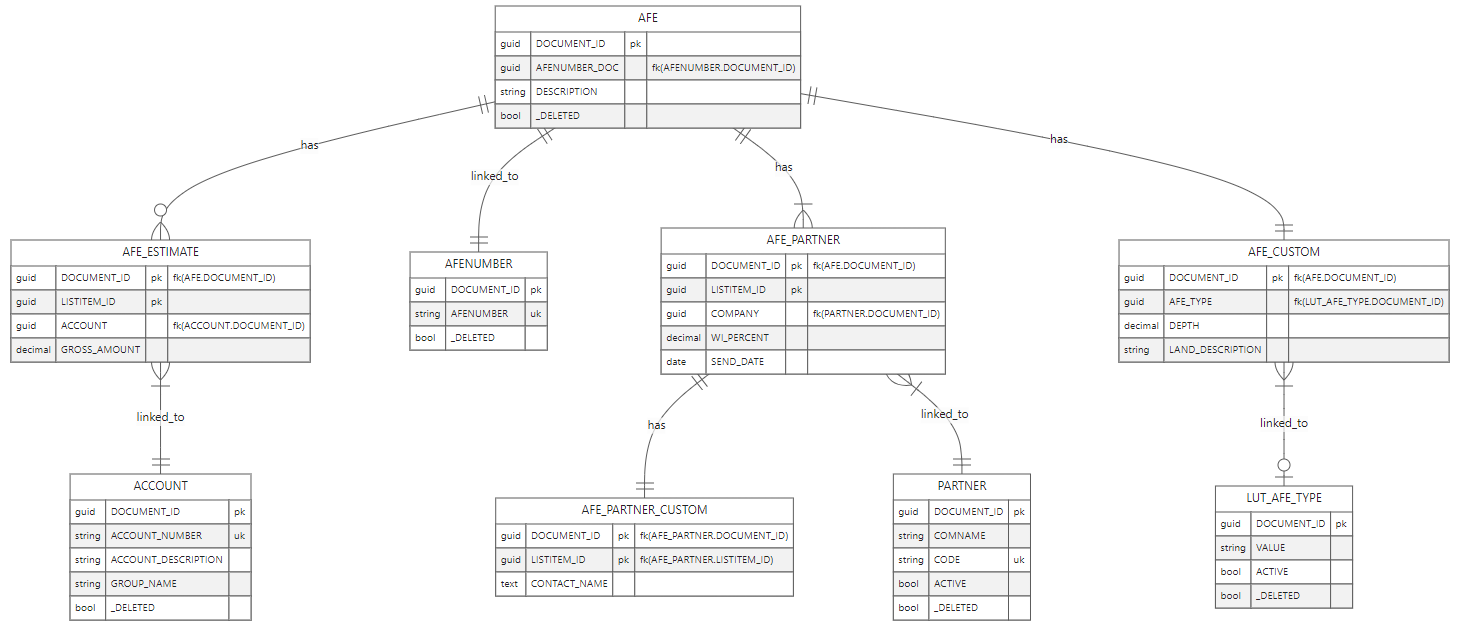
Each Document Type (AFE, USER, WELL, SITE, ...) in Execute consists of a main/root table (whose name matches the Document Type name - i.e. "AFE") and zero or more additional tables (i.e. "AFE_CUSTOM", "AFE_ESTIMATE", "AFE_PARTNER", "AFE_PARTNER_CUSTOM").
-
A DOCUMENT_ID is the unique ID for a document/record in Execute and is the common key for records in the main/root table, and all additional tables.
-
Additionally, records in child tables (i.e. Partners on an AFE, GeoProg on a Job, ...) have an additional key LISTITEM_ID which is used to identify a particular table entry.
The following simplified diagram attempts to visually show the relationships for a subset of an AFE.
Differences between Warehouse Schema and Execute Schema
The reporting views have the following differences from the Execute schema.
There are no *_H history tables. These tables were notoriously difficult to query since data is stored sparsely. History is captured and preserved on a go forward basis in EXECUTE_DOCUMENTS.
When enabling Execute's warehouse publishing, Execute publishes the current state for each document and then all subsequent versions. This means that historical history, created prior to enabling the warehouse publishing, is not exported to the warehouse database.
There are no *_DOC or *_DOC_V tables. These tables were used for storing additional metadata about documents and their version (Is it Deleted? Who made this version? When? ...). A common error when querying the Execute schema was forgetting to join on the *_DOC table and filter out soft-deleted rows. These fields are now on the main table so that queries are simpler.
The main/root document table now includes the following additional meta-data fields:
| Field | Type | Description |
| _DELETED | BOOLEAN | Is this document deleted? |
| _AUTHOR | GUID | Document ID for the user who created this version of the document |
| _VERSION | INT | Version number for this version of the document |
| _DATE | TIMESTAMP | Timestamp for this version of the document |
The main/root document table for some documents were renamed to make them more consistent with other documents in the system.
| Old Table Name | New Table Name | Note |
| USERS | USER | "USER" is a reserved word in SQL Server so you may need to enclose it in quotes in your queries. |
| PARTNERS | PARTNER | |
| ACCOUNTS | ACCOUNT |
Security Considerations
Execute's Data Warehousing functionality publishes Execute data to a public-facing database server that isn't operated by Quorum. As such, it is important to be aware that this does come with some degree of risk and that, while Quorum takes reasonable steps to secure the data in transit, Quorum can not be responsible for the security of the data in the Warehouse Database.
IMPORTANT – READ CAREFULLY
Quorum takes data security seriously and implements various measures to protect your information. However, please be aware that no system can guarantee absolute security, and there are inherent risks
associated with the transmission and storage of data over the internet or any electronic system. By using our servicesor providing us with your data, you acknowledge and accept these risks. The Shared Responsibility Model (as described below and, as applicable, in the documentation regarding the software and services provided by Quorum) identifies the responsibilities of Quorum and the Customer regarding security and management of applicable systems, software, and data.
Quorum is responsible for:'
The security of the Quorum-operated environment
Implementing reasonable measures to protect Customer data within the Quorum-operated environment
Enabling data encryption and usage of secure communication protocols (e.g. HTTPS for web endpoints)
Provision of a facility to enable customers to leverage multifactor authentication to authenticate against Quorum hosted applications.
Informing customers of any significant data or security events within a reasonable timeframe.
The Customer is responsible for:
The data provided by the Customer (or any user that the Customer allows to access the Quorum software or services), including the legality, reliability, integrity, accuracy, consistency, and quality of such data
Using and securing the Customer’s hardware, software, applications, data, and operating systems (which may includeintegration middleware), including by implementing appropriate updates and security patches
Implementing appropriate measures to prevent unauthorized access to or use of the Quorum software or services, including maintaining the confidentiality of users’ credentials
Any software applications developed by or for the Customer for interaction with data generated by use of the Quorum software and services (if such applications are permitted under the agreement between Quorum and the Customer), including any updates necessary to access, communicate, or interoperate with the Quorum software and services
Implementing appropriate measures to protect Customer data stored on the Customer’s own systems and other systems that are not operated by Quorum
Use of any output from the Quorum software or services that is stored on the Customer’s own systems or other systems that are not operated by Quorum (including if such output was previously transmitted by Quorum to the Customer)
Use of any APIs that access, communicate, or interoperate with any Quorum software or services, including ensuring that any such APIs function as intended (or will continue to function as intended after a version change) or will be maintained (in each case, except to the extent that Quorum has expressly agreed in the agreement between Quorum and the Customer to maintain an applicable API)
Quorum will consider a Customer’s request to transmit the Customer’s data that is hosted or processed by Quorum to a secure system that is not owned or operated by Quorum. Once mutually agreed Quorum will transfer such data using reasonable industry practices to secure the data in transit. After Quorum has transmitted any Customer data to the Customer, the Customer will be fully responsible for such data (including the protection and use thereof), and Quorum will have no further responsibility for such data.
The Customer understands and acknowledges that while Quorum will use reasonable practices for its responsibilities described above, Customer data may not be encrypted at all times, such as in case of transmission of any mutually agreed SMS (Short Message Services) text messages.
Network-level Permissions
Connections from Quorum-hosted Execute environments will come from the following IPv4 ranges. You can use these to limit connectivity to your warehouse database.
-
74.200.29.240/28
-
98.158.83.112/28
Configuration & Usage
The steps for configuring publishing to Snowflake and AzureSQL are as follows:
Snowflake
To enable the publishing of Execute data to Snowflake, create a new Plugin (Tools > Configuration > Plugins (view items) > Create New Plugin), click "Copy from Sample" and select the "snowflake.config" plugin ("plugins_available/integrations/product_integrations/warehouse/snowflake.config"). Typically, no changes are required to this file.
Create a new database connection string called "Snowflake" for your Snowflake database ("Tools > Configuration > Connection Strings (configure) > Add New Connection String"). Here is a template connection string.
Provider Type=SnowflakeProvider; account=ACCOUNT_IDENTIFIER; User=USER; db=DATABASE; schema=SCHEMA; Password=@@@SNOWFLAKE_PASSWORD; Warehouse=COMPUTE_WAREHOUSE
| Parameter | Description |
| ACCOUNT_IDENTIFIER | Will be a value in the form of abcdefg-hi12345. The first component (abcdefg) is your "Organization" identifier, while the second component (hi12345) is your "Account" identifier. |
| USER | The Snowflake Username Execute will connect with (must have full permissions to the configured DATABASE). |
| DATABASE | The name of the Snowflake database Execute will write to (must exist, and be empty). |
| COMPUTE_WAREHOUSE | The name of the Snowflake Compute Warehouse that will be used for queries initiated by Execute. |
Additionally, you need to add a new external credential "SNOWFLAKE_PASSWORD" to "Tools > Configuration > External Credentials (configure) > Add New Credential" with the password for your configured Snowflake user.
Do not embed your Snowflake password in the database connection string as it will be stored unencrypted in Execute's configuration and can be retrieved by administrators in Execute. Instead, be sure to use Execute's secure external credential store (as described above) so that the credential is encrypted and can never be retrieved by a user of Execute.
Finally, restart Execute to activate the plugin ("Tools > Restart Execute Service")
Next, fine-tune the Snowflake specific configuration settings in "Tools > Configuration > Settings (configure)".
| Setting | Default Value | Description |
| Snowflake Batch Size | 50,000 | Number of Execute documents to include in a batch sent to Snowflake. Rarely will this need to be adjusted. |
| Snowflake Create Views | NORMAL |
Options are:
|
| Snowflake Queue Wait | 600 | How often (in seconds) the buffer of updated documents will be sent to Snowflake. The minimum value for this setting is "30" (seconds). Setting this too frequent will prevent your Snowflake warehouse from suspending and will cost more money. |
Finally:
-
Instruct Execute to create (or update) the required tables and, if configured, reporting views by running "Tools > Synchronization > Snowflake Schema Publisher (run)".
-
Instruct Execute to export the current version of ALL documents in Execute to Snowflake by running "Tools > Synchronization > Snowflake Document Publisher (run)".
At this point, your Snowflake environment will contain a copy of all document-level data captured in Execute and Execute will automatically keep that data up-to-date (at the interval configured) as changes are made within Execute.
Rerunning the "Snowflake Schema Publisher" sync job will update the reporting views to reflect recent schema changes in Execute (i.e. as a result of adding a new custom field or performing a software update).
Rerunning the "Snowflake Document Publisher" sync job will republish the current version of all documents to Snowflake. This is primarily useful for situations where a backend SQL script made changes to Execute's data that wouldn't be detected by the automated publishing.
Azure SQL
To enable the publishing of Execute data to AzureSQL, create a new Plugin ("Tools > Configuration > Plugins (view items) > Create New Plugin"), click "Copy from Sample" and select the "sqlwarehouse.config" plugin ("plugins_available/integrations/product_integrations/warehouse/sqlwarehouse.config"). Typically, no changes are required to this file.
Create a new database connection string called "SQLWarehouse" for your AzureSQL database ("Tools > Configuration > Connection Strings (configure) > Add New Connection String").
Provider Type=SqlServerProvider; Data Source=SERVER_NAME; Initial Catalog=DATABASE_NAME; User ID=USER_ID; Password=@@@SQLWAREHOUSE_PASSWORD; Integrated Security=False; Min Pool Size=10; MultipleActiveResultSets=True;Encrypt=true
| Parameter | Description |
| SERVER_NAME | The hostname of the AzureSQL database instance (typically something like "myserver.database.windows.net") |
| USER_ID | The AzureSQL Username Execute will connect with (must have full permissions to the configured database). |
| DATABASE_NAME | The name of the schema Execute will write to (must exist, and be empty). |
When configuring Execute to publish data to AzureSQL, it is required that you enable SQL Server authentication by including Encrypt=true in the configured connection string. Failing to do this means that your Execute data would be transiting the public Internet (between Quorum and Azure) in an unencrypted state.
Additionally, you need to add a new credential "SQLWAREHOUSE_PASSWORD" to "Tools > Configuration > External Credentials (configure) > Add New Credential" with the password for your configured AzureSQL user.
Finally, restart Execute to activate the plugin ("Tools > Restart Execute Service")
Next, fine-tune the AzureSQL specific configuration settings in "Tools > Configuration > Settings (configure)".
| Setting | Default Value | Description |
| SQL Warehouse Batch Size | 1000 | Number of Execute documents to include in a batch sent from AzureSQL. Rarely will this need to be adjusted. |
| SQL Warehouse Create Views | NORMAL |
Options are:
|
| SQL Warehouse Queue Wait | 600 | How often (in seconds) the buffer of updated documents will be sent to AzureSQL. |
Finally:
-
Instruct Execute to create (or update) the required tables and, if configured, reporting views by running "Tools > Synchronization > SQL Warehouse Schema Publisher (run)".
-
Instruct Execute to export the current version of ALL documents in Execute to AzureSQL by running "Tools > Synchronization > SQL Warehouse Document Publisher (run)".
At this point, your AzureSQL environment will contain a copy of all document-level data captured in Execute and Execute will automatically keep that data up-to-date (at the interval - Queue Wait - configured) as changes are made within Execute.
Rerunning the SQL Warehouse Schema Publisher sync job will update the reporting views to reflect recent schema changes in Execute (i.e. as a result of adding a new custom field or performing a software update).
Rerunning the SQL Warehouse Document Publisher sync job will republish the current version of all documents to AzureSQL. This is primarily useful for situations where a backend SQL script made changes to Execute's data that wouldn't be detected by the automated publishing.