
Manual for the Data Selection Tool which facilitates building live pick-lists from data in external systems
Aucerna Execute supports a generic mechanism called “Data Selection” that allows administrators to build selection screens that allow users (typically AFE originators) to select records from an external system and copy that information onto the AFE, as a way of avoiding re-keying that information. For example:
- Allow the originator to select a cost center from the list of cost centers created by the accounting system. When the cost center is selected, the primary well UWI and well name may also be automatically filled out.
- Allow the originator to select a well from a drilling/completions system and, upon selection, copy the well header information (UWI, well name, state/province, lat/long, depths, etc) onto the AFE
- Allow the originator to select a DOI from the land system and automatically copy the DOI header information, participants, working interests and operator onto the AFE.
Multiple data selections can be configured.
1 Usage
The specifics of the data selection will vary depending on how you have it configured but generally it will look something like the following:
- While creating the AFE, originators will click the “Select _” button in their toolbar. There may be more than one of these.
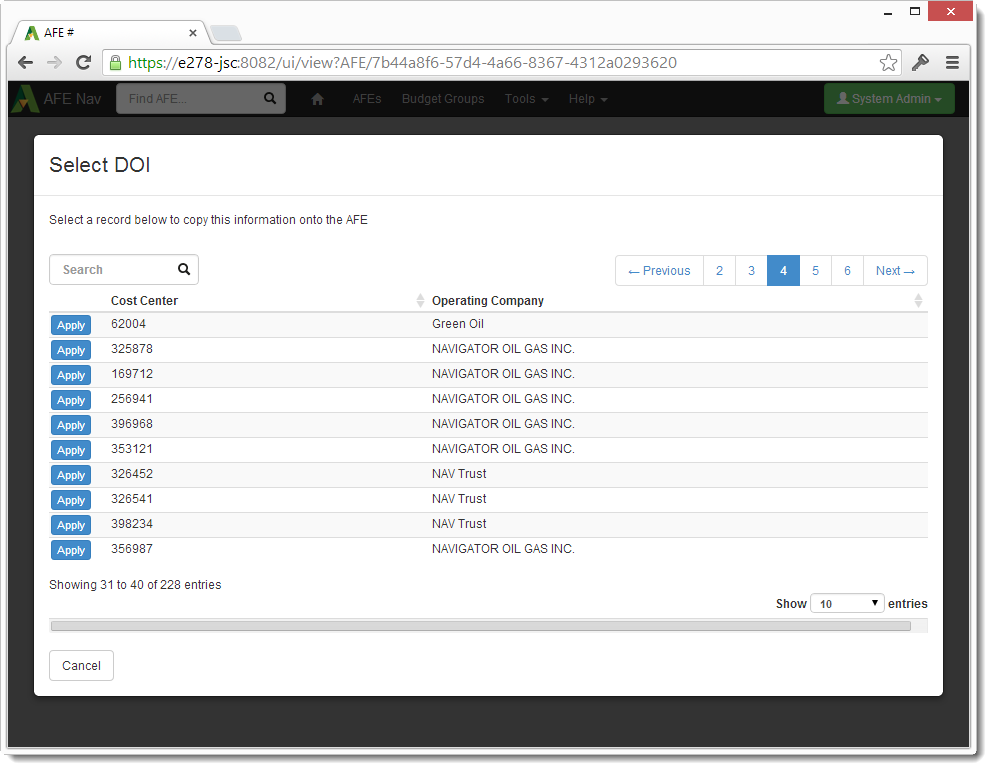
- This will present the selection screen which is a sortable/searchable live view on the source data.
- Use will choose the Apply button and the data from that record (in this case: the cost center number, and DOI) will be copied onto the AFE.

2 Configuration
Sample configuration files for the Data Selection tool are available in the “plugins_available\data_selection” folder under your Aucerna Execute Service and these provide the starting point for setting up a new data selection. Make a copy of the template that is the closest match to what you are configuring and place it into the “plugins” folder, customize it, remove the .sample suffix, and restart the Aucerna Execute service. The samples include:
- data_selection.config.sample: Sample data selection that pulls data from the Aucerna Execute database connection (potentially accessing 3rd party information through a DBLink/View). This updates AFE header information. This is the most common scenario.
- data_selection_doi.config.sample: Sample data selection that pulls DOI information (participants, working interest, and operator) in additional to some AFE header information.
- data_selection_well.config.sample: Sample data selection that pulls well lists in additional to some AFE header information.
- data_selection_external.config.sample: Sample data selection that supports initiating a connection to a 3rd party database (SQL Server/Oracle) and pulling data directly from that source.
When you setup a data selection you will be configuring:
- How the selection is presented to the users:
- Is it in the Toolbar or “More” menu?
- What is its name?
- Who can run this selection and when?
- baseQuery is a partial select statement (just the SELECT and FROM clauses) that is used to provide the list of options to show to the user, and provide data to update onto the AFE. It has a unique ID column, and its other columns will be displayed to the user, unless they are hidden by giving them a name that begins with an underscore.
- filterClause is an expression that will be used in the WHERE clause to filter the data shown to the user. It has syntax to filter on the search value entered by the user, and data that already exists on the AFE. The string {{FILTER}} will be replaced with the user’s entered search value. Data from the AFE can be attached to parameters in the section. They are referred to using the @parameter notation.
- idClause is used to construct a separate WHERE clause to retrieve a row based on its unique ID. It is generally just “idColumn = @id” where idColumn is the same as the column used as the ID in the . For example, if the base query is: SELECT entity_id ID, name "Cost Center Name", value "Cost Center Number" from entities then the idClause value would be: entity_id = @id
- Sorting: how to sort the results from the query
- Which columns to copy on the AFE
- Candidates are: any general fields (description, budget year, etc), custom fields, primary well, and primary AFE attribute fields
- Which columns to show the user when they are making their selection.
2.1 Sample Configuration
The configuration files are written as working samples with in-line documentation to help guide you through the configuration.
The following is a sample selection configuration file that is configured to pull data cost center information (number, name and description) from a sample table “COSTCENTER_SOURCE” and allow users to copy this on the AFE. This provides a working starting point for building your own data selections.
When defining your source view/table it is imperative that the column types match the column types of the corresponding column in Aucerna Execute. If the field in Aucerna Execute is a VARCHAR2 field, the field in your table/view that you are mapping to that field must also be VARCHAR2.
| Column | Type | Description |
|---|---|---|
| COSTCENTER_NUMBER | VARCHAR(10) | Cost Center Number (unique key for cost centers) |
| COSTCENTER_NAME | VARCHAR(50) | Short name for cost center. Users search on this |
| COSTCENTER_DESCRIPTION | VARCHAR(2000) | Long description for cost center |
<castle>
<components>
<component
id="dataSelection_{##UNIQUE##}"
type="Eni.AfeNavigatorServer.Services.Web.Methods.Util.DataSelection.DataSelection"
service="Eni.AfeNavigatorServer.Services.Web.Methods.Util.DataSelection.IDataSelection">
<parameters>
<!-- The ID must be unique across all data selectors. It should consist only of letters and digits -->
<id>costCenterSelection</id>
<!-- The name is used for the button title. This is what users see. It should be short -->
<name>Select Cost Center</name>
<!-- The rule (below) can modified to control when this data selection is enabled -->
<ruleName>StandardUnreleasedOnlyAfeEditRule</ruleName>
<!-- Do not modify the source parameter below -->
<source>${dataSelectionSource_{##UNIQUE##}}</source>
<!-- In Toolbar? Otherwise in "more" menu -->
<inToolbar>true</inToolbar>
</parameters>
</component>
<component
id="dataSelectionSource_{##UNIQUE##}"
type="Eni.AfeNavigatorServer.Services.Web.Methods.Util.DataSelection.DatabaseQueryDataSelectionSource"
service="Eni.AfeNavigatorServer.Services.Web.Methods.Util.DataSelection.IDataSelectionSource">
<parameters>
<!-- The base query selects the list of fields that are available to the data selection tool. -->
<!-- * The first field must be a unique string called "id". -->
<!-- * Not all of the fields selected need to be copied onto the target document. They can be informational. In this case the column name is shown directly to the user. You can control what the user sees be aliasing the column -->
<!-- * Columns prefixed with "_" are not shown to users but can still be copied to target document -->
<baseQuery>select costcenter_number id, costcenter_name, costcenter_number, costcenter_description from COSTCENTER_SOURCE</baseQuery>
<!-- The filter clause is used to filter out rows from the dataset based on -->
<!-- 1) the filter string typed by the user (all occurrances of '{{FILTER}}' are replaced with user filter string -->
<!-- 2) who the user is (all occurances of '{{USER}}' are replaced by the user DOCUMENT_ID) -->
<!-- 3) properties of the document (@parameter from filterFields below) -->
<filterClause>upper(costcenter_number) like upper('%{{FILTER}}%')</filterClause>
<!-- Default order clause -->
<defaultOrderBy>order by costcenter_number</defaultOrderBy>
<!-- Filter clause to find a row by its ID -->
<idClause>costcenter_number = @id</idClause>
<!-- What type of document this data selection applies to -->
<documentType>AFE</documentType>
<!-- Properties from document to make available to filterClause -->
<!-- There do not need to be filterFields defined -->
<!-- Should be: <item>parameter,PATH</item> -->
<filterFields>
<array>
</array>
</filterFields>
<!-- For columns that should be copied onto the target document, a mapping of column name to document field path -->
<!-- Should be: <item>column,PATH</item> -->
<!-- Examples: -->
<!-- <item>budgeted,CUSTOM/BUDGETED</item> -->
<!-- <item>uwi,PRIMARY_WELL/UWI</item> -->
<!-- <item>wellname,PRIMARY_WELL/NAME</item> -->
<columnMap>
<array>
<item>costcenter_number,CUSTOM/COSTCENTER_NUMBER</item>
<item>costcenter_name,CUSTOM/COSTCENTER_NAME</item>
<item>costcenter_description,CUSTOM/COSTCENTER_DESCRIPTION</item>
</array>
</columnMap>
<OlsonIanaTimezone>Etc/UTC</OlsonIanaTimezone> <!-- optional olson/iana time zone for source date/time zone. Default is service local. -->
</parameters>
</component>
</components>
</castle>
3 DOI Selection
DOI selection is somewhat more complex than a standard data selection because, in addition to pulling header information, we are also pulling a list of participants and their interests. To facilitate this we require two separate queries: header data and partner data. Roughly the queries provided would have the following structure:
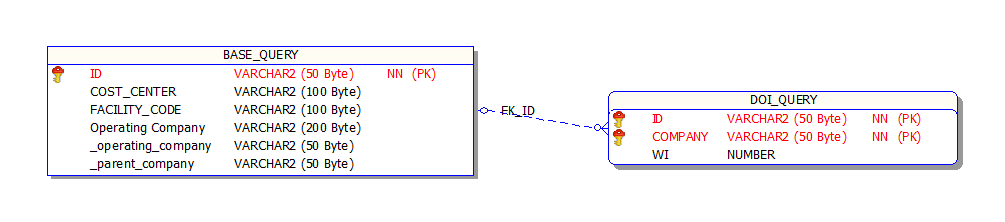
The “baseQuery” is responsible for:
- Providing a unique string identifier (id) that is used as the key for the DOI data
- Any “header” fields (COST_CENTER and FACILITY_CODE) above
- Identifying Operator and Parent Company (_operating_company and _parent_company).
- In the above case, we’ve also included the “Operating Company” name as an additional column for reference. That field is display only and not used directly.
The “doiQuery” is responsible for:
- List of companies and their working interest.
The “doiQuery” data must obey the following rules:
- It MUST contain a record for the Operating Company.
- It MUST contain a record for the Parent Company.
- The working interests MUST add to EXACTLY 100.