
A high-level overview of the Aucerna Execute schema
Because the Aucerna Execute schema is dynamic (adding a custom field or table changes adds that field or table directly to the schema), and large (> 300 tables), it is not possible to produce a single static document or ERD for the Aucerna Execute schema. Fortunately, most of the data in the Aucerna Execute schema is stored in a consistent structure, and once that structure is understood, navigating the schema becomes straightforward.
The following document serves as an introduction to how data is organized in the Aucerna Execute schema.
Identifiers
In previous versions of Aucerna Execute auto-incrementing numeric identifiers were used for unique identifiers on objects within the database. These were used to uniquely identify AFEs (AFEID), accounts, partners, users, AFE Types, etc. These still are used in some places in Aucerna Execute but they are being phased out.
The majority of unique identifiers in Aucerna Execute are GUIDs (very large random strings like “fde674e8-380a-4a0d-b168-2b07c6611af2”). This has several advantages over the sequential identifiers we used in previous versions:
- Concurrency – Because the AFE service is multi-threaded we do not have to synchronize the generation of unique IDs across the environment. This means less code complexity (no complicated locking logic) and better performance with bulk insert operations.
- External updates – Adding records by SQL is safer because there isn’t a separate last_generated_value field to keep in sync with the data (see Update Database Through Scripts).
- Possible data merges – In the future we would like to make merging data between multiple Aucerna Execute environments easier. Having globally unique identifiers on everything will help this.
Document Tables
An Aucerna Execute database is composed of multiple entities called “Documents”. Each Document has a defined structure (based on the underlying schema) and uses configured meta-data to define the workflow, permissions and display. The following are examples of the types of things that are Documents in Aucerna Execute:
- AFE
- RTD
- Account
- Partner
- User
- Position Rule (New-style Approval or System Review rules)
All Documents inherit some common functionality such as loading/saving/caching, permission enforcement, audit history, customization, APIs, user interface elements, etc. All Documents have a similar structure when stored in the database.
Here is an example schema for the Account Document.
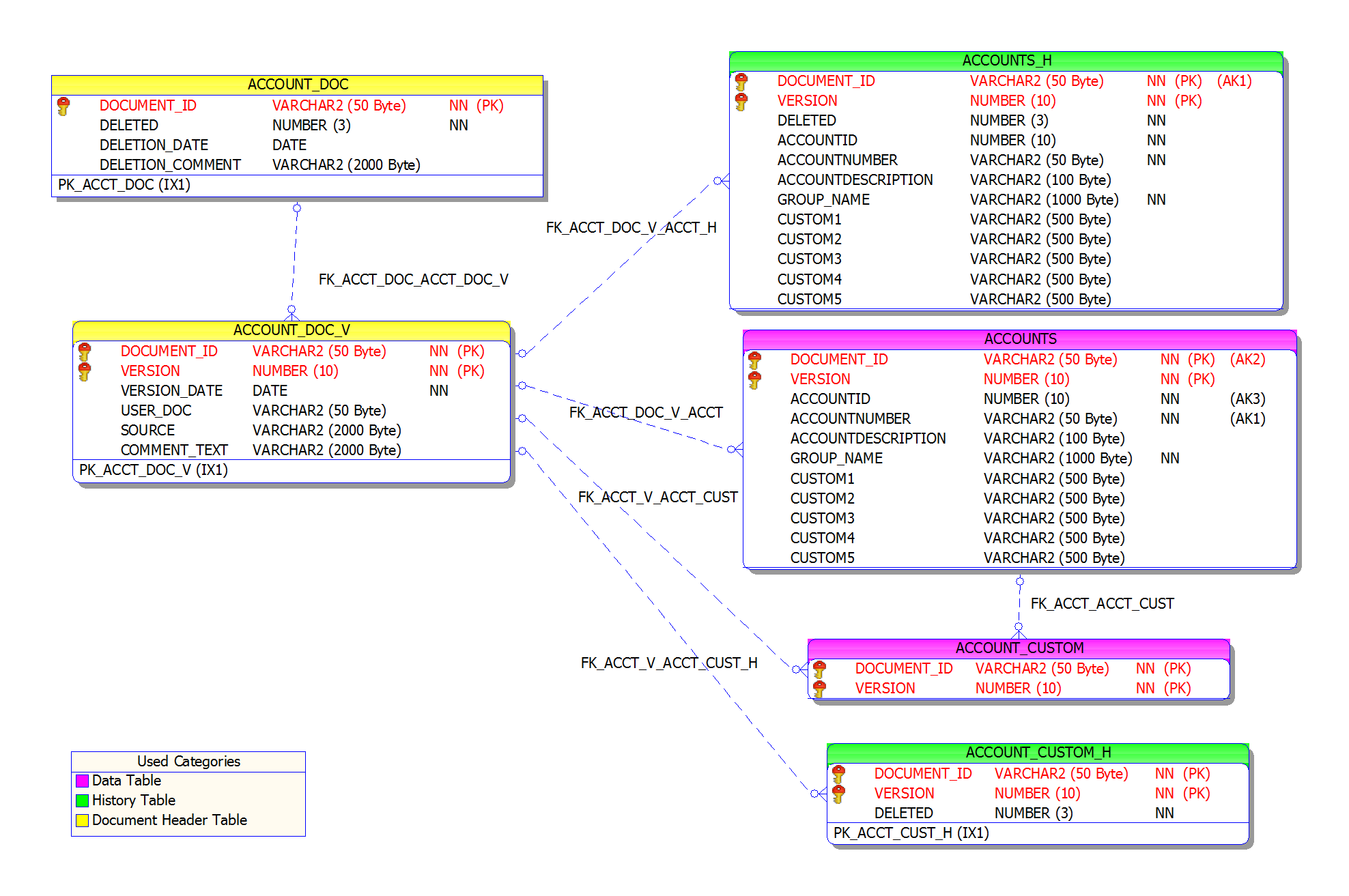
Click image to expand or minimize.
The master document table ends in “_DOC” (ACCOUNT_DOC). It introduces the document and tracks whether it is deleted or not.
The versions table identifies each version of a document, who created it, the date and some comments about the version (whether it was created by a script, for example). The document version tables end in “_DOC_V” (ACCOUNT_DOC_V). There will be one row in this table for every “edit” of a document (an edit may be comprised of many individual field changes).
The main table for a document has no suffix (ACCOUNTS) and is responsible for storing most of the data. It may also have a series of child tables (ACCOUNT_CUSTOM). The main table only stores the latest data for that record. Child tables are typically prefixed by the document name (ACCOUNT) and will have a foreign key to explain the relationship. (The main AFE document table is an exception; “AFE_TOP”)
In the case of the ACCOUNTS document, ACCOUNT_CUSTOM is the child table where all account custom fields (added through the administrative tools) will be located. A similar pattern is used for users, partners and AFEs so that stock fields and administrator created custom fields are separate.
History tables have the suffix “_H” (ACCOUNTS_H) and store previous versions of records from the matching main table (they’ll have the same fields). Aucerna Execute does sparse versioning so, for a particular document version, there may not be a corresponding history record; it depends on whether the record was changed. Child tables also have matching history tables with the “_H” suffix.
When documents in Aucerna Execute are deleted they are simply flagged as deleted in the “_DOC” table. Consequently, when querying the Document tables it is usually necessary to join on the “_DOC” table and only show records where DELETED equals “0”.
For example: the following query will return the account number, account description and any custom account fields for all active (not deleted) accounts in Aucerna Execute.
select
accounts.ACCOUNTNUMBER,
accounts.ACCOUNTDESCRIPTION,
account_custom.*
from
account_doc
join accounts on (accounts.DOCUMENT_ID = account_doc.document_id and account_doc.DELETED=0)
join account_custom on (accounts.document_id = account_custom.document_id);
The AFE Tables
As of Aucerna Execute 2017, the AFE falls entirely within this new document structure. The structure is a bit more complex than the above example because there are more tables involved but it works the same way. Here is a partial ERD for the AFE tables.
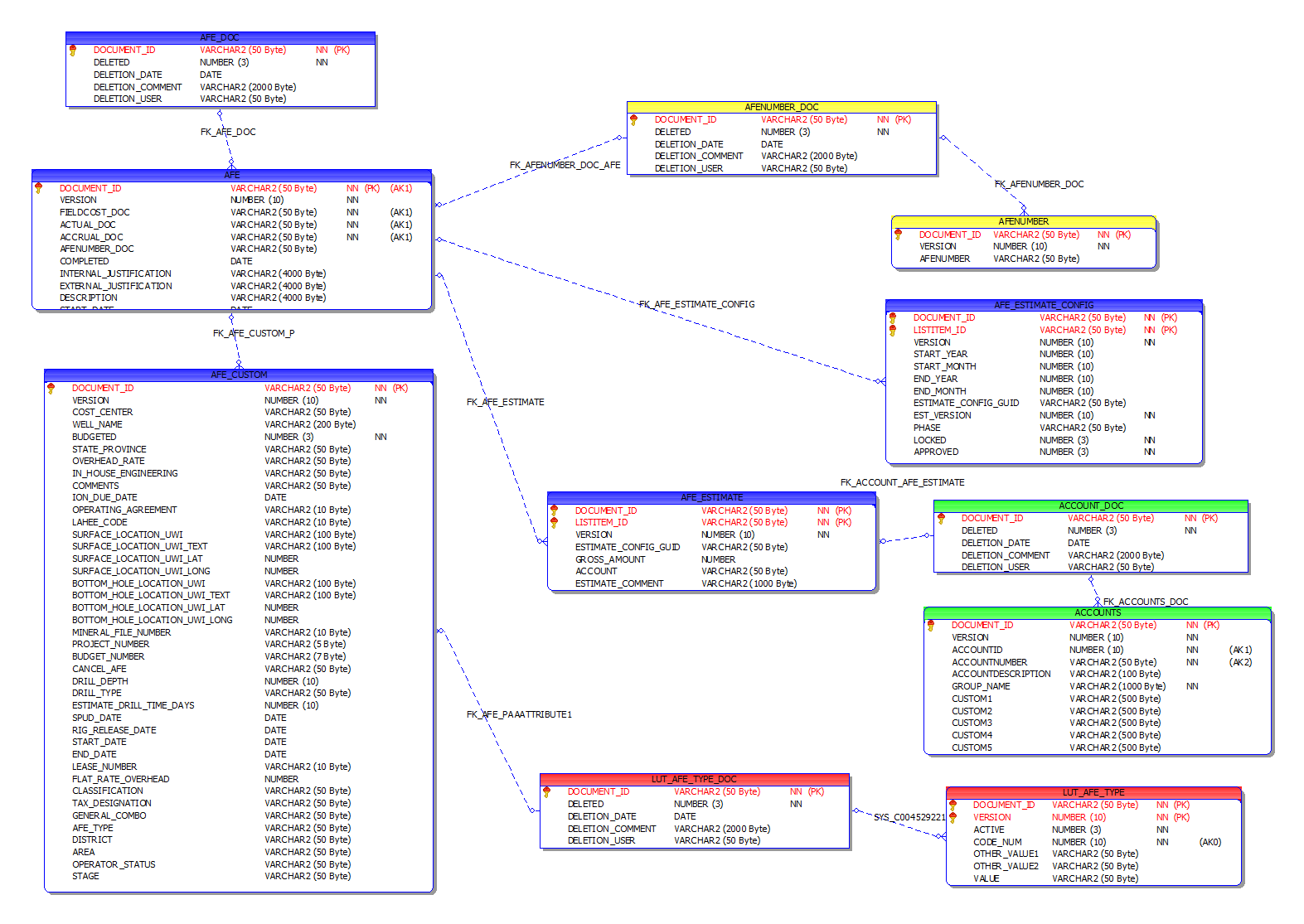
Click image to expand or minimize.
And here is some sample SQL that pulls commonly accessed information from the AFE.
select
afe_doc.document_id, -- Unique identifier for AFE
afenumber.afenumber, -- AFE Number
afe.description, -- AFE Description
afe.status, -- AFE Status (UNREL, ROUTED, REL, IAPP, FAPP, PREJ, REV, SUP)
lut_afe_type.value afe_type, -- Display value for AFE Type (Attribute 1 in sample database)
accounts.accountnumber, -- Account Number
accounts.accountdescription, -- Account Description
afe_estimate_config.est_version, -- Estimate Version
afe_estimate.gross_amount -- Gross Estimate for Account
from
afe_doc
join afe on (afe.document_id = afe_doc.document_id and deleted=0)
join afe_custom on (afe_custom.document_id = afe_doc.document_id)
join afenumber on (afenumber.document_id = afe.afenumber_doc)
join afe_estimate on (afe_estimate.document_id = afe.document_id)
join afe_estimate_config on (afe_estimate_config.document_id = afe.document_id and afe_estimate_config.estimate_config_guid = afe_estimate.estimate_config_guid)
join accounts on (accounts.document_id = afe_estimate.account)
join lut_afe_type on (afe_custom.afe_type = lut_afe_type.document_id)
where
afe.status not in ('REV','SUP')
order by
afenumber.afenumber,
accounts.accountnumber
Updating Data Through Scripts
To improve performance, Aucerna Execute caches data very aggressively. The consequence to this is that you have to be careful doing updates directly to the database.
In general, NEVER update data in the Aucerna Execute database (through SQL) while the server is running. While the server is stopped changes directly to the data in the database are safe although if your changes create bad data there is the possibility the service may fail to start.
Our preferred approach for data updates to Document data (AFEs, Users, Partners, …) is that those changes be made using our synchronization tools: we provide a simplified staging table for the data needing to be pushed into Aucerna Execute and the service copies that data onto the AFE when it is safe to do so. This has several advantages:
- Validation of changes. The system will not apply changes that would produce an invalid AFE (or other “Document”).
- Simplicity. It shields external systems from the details of the Aucerna Execute tables and their relations. The staging table might be as simple as (AFENUMBER, CLOSED, CLOSED_DATE) while the SQL to do this update manually would be much more complex.
- Version Independence. Because your code is not tied directly to the schema, it will continue to work across Aucerna Execute upgrades.
- History. Changes made in this fashion will have valid audit history so that users, and auditors, can see when data changed and what value was in use previously. Changes direct to the database don’t have this history tracking.
- Locking. Changes are only applied when it is safe to do so and while nobody is editing the document. This means your code can be simpler and the changes will never be overwritten by a user who is currently working on the AFE. This also means that changes made in this way are safe to run while users are in the system.
Custom Fields
Most document types support the addition of custom / user-defined fields.
- On custom document types (those prefixed with LUT_), custom fields are found directly on the main table (see Custom Lists below)
- On Energy Navigator provided document types (AFE, RTD, User, Partner, Account, etc.), custom fields are found on the associated “_CUSTOM” table (ie. AFE_CUSTOM for the AFE)
When a new custom field is added within Aucerna Execute a new field is added to the schema based on the display name of the field (example: A 200 character text “Drill Type” would become VARCHAR(200) “DRILL_TYPE”).
Custom Lists
In the case of new custom drop-down lists, a set of new tables are created to model this new dropdown list as a new “Document” in Aucerna Execute. All user created “Document” types are prefixed by “LUT_” in the schema but otherwise have the same “Document” structure described above. Custom fields can, in turn, be added to this new document type to track additional data relevant to that list record.
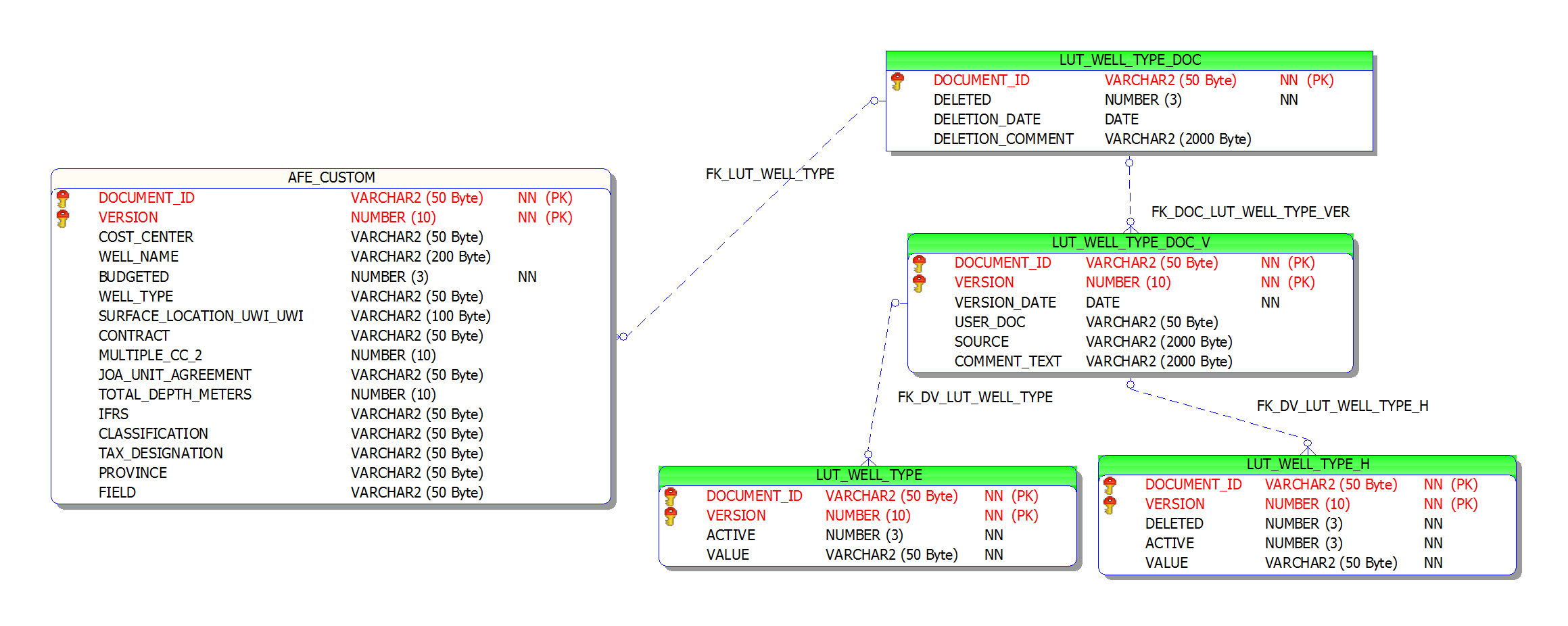
Click image to expand or minimize.
In the above example we have a “WELL_TYPE” custom field list. Currently this list value only has a single “VALUE” field but, through the user interface, additional fields can be added to track other information with the WELL_TYPE (in this case, those fields are added directly to LUT_WELL_TYPE and LUT_WELL_TYPE_H). For example: I might add an “ACCTG_CODE” field to store the value recognized by my accounting system to simplify future integrations.